Some serious updates on open source AI while OpenAI, Runway and Suno have been unveiling their new models and making deals with content providers and streaming services to overcome copyright issues.
Lets start out with cogvideox, perhaps the best open source video model to date, there are various ways to run it including comfyui nodes
CogVideo & CogVideoX
Experience the CogVideoX-5B model online at 🤗 Huggingface Space or 🤖 ModelScope Space
📚 View the paper and user guide
📍 Visit QingYing and API Platform to experience larger-scale commercial video generation models
Project Updates
- 🔥🔥 News:
2025/03/24: We have launched CogKit, a fine-tuning and inference framework for the CogView4 and CogVideoX series. This toolkit allows you to fully explore and utilize our multimodal generation models. - 🔥 News:
2025/02/28: DDIM Inverse is now supported inCogVideoX-5BandCogVideoX1.5-5B. Check here. - 🔥 News:
2025/01/08: We have updated the code forLorafine-tuning based on thediffusersversion model, which uses less GPU memory. For more details, please see here. - 🔥 News:
2024/11/15: We released theCogVideoX1.5model in the diffusers version. Only minor parameter adjustments are needed to…
Temporal lab is a python based video suite that combines cogvideox with ollama to provide integrated LLM and video generation services for filmmakers, artists, etc
 TemporalLabsLLC-SOL
/
TemporalPromptEngine
TemporalLabsLLC-SOL
/
TemporalPromptEngine
A comprehensive, click to install, fully open-source, Video + Audio Generation AIO Toolkit using advanced prompt engineering plus the power of CogVideox + AudioLDM2 + Python!
Temporal Prompt Engine: Local, Open-Source, Intuitive, Cinematic Prompt Engine + Video and Audio Generation Suite for Nvidia GPUs
##NOW FEATURING custom 12b HunYuanVideo script with Incorporated MMAudio for 80gb cards.








##MASSIVE UPDATE TO INSTRUCTIONS BELOW COMING VERY SOON (12/11/2024)
I am looking for a volunteer assistant if you're interested reach out at [email protected] - This is going to a webapp version VERY soon.
Table of Contents
- Introduction
- Features Overview
- Installation
- Quick Start Guide
- API Key Setup
- Story Mode: Unleash Epic Narratives
- Inspirational Use Cases
- Harnessing the Power of ComfyUI
- Local Video Generation Using CogVideo
- Join the Temporal Labs Journey
- Donations and Support
- Additional Services Offered
- Attribution and Courtesy Request
- Contact
- Acknowledgments
Introduction
Welcome to the Temporal Prompt Engine a comprehensive framework for building out batch variations or story sequences for video prompt generators. This idea was original started as a comfyUI workflow for CogVideoX but has since evolved into…
This is not new news but I recently tested invoke AI, it is an interesting alternative for those who are looking for the modular aspects of comfyui without the complexity
https://invoke-ai.github.io/InvokeAI/installation/installer/#running-the-installer
Finally some cutting edge new generation Image models, the long awaited SD 3.5 and the Flux model by their competitors.
https://comfyanonymous.github.io/ComfyUI_examples/sd3/?ref=blog.comfy.org
https://stable-diffusion-art.com/flux-comfyui/
OmniGen is a unified image generation model that can generate a wide range of images from multi-modal prompts. It is designed to be simple, flexible, and easy to use. We provide inference code so that everyone can explore more functionalities of OmniGen.
Existing image generation models often require loading several additional network modules (such as ControlNet, IP-Adapter, Reference-Net, etc.) and performing extra preprocessing steps (e.g., face detection, pose estimation, cropping, etc.) to generate a satisfactory image. However, we believe that the future image generation paradigm should be more simple and flexible, that is, generating various images directly through arbitrarily multi-modal instructions without the need for additional plugins and operations, similar to how GPT works in language generation.
VectorSpaceLab
/
OmniGen
OmniGen: Unified Image Generation. https://arxiv.org/pdf/2409.11340
OmniGen: Unified Image Generation
News | Methodology | Capabilities | Quick Start | Finetune | License | Citation
We are hiring FTE researchers and interns! If you are interested in working with us on Vision Generation Models, please concat us: [email protected]!
1. News
- 2025-06-16:🔥🔥OmniGen2 is released at https://github.com/VectorSpaceLab/OmniGen2. Welcome to use and give some feedback.
- 2025-02-12:🔥🔥OmniGen is available in Diffusers.
- 2024-12-14:🚀️🚀Open-source X2I Dataset
- 2024-11-03: Added Replicate Demo and API:
- 2024-10-28: We release a new version of inference code, optimizing the memory usage and time cost. You can refer to docs/inference.md for detailed information.
- 2024-10-22: We release the code for OmniGen. Inference: docs/inference.md Train: docs/fine-tuning.md
- 2024-10-22: We release the first version of OmniGen. Model Weight: Shitao/OmniGen-v1 HF Demo: 🤗
- 2024-09-17:⚡️⚡️We release the first OmniGen Report: ArXiv
2. Overview
OmniGen is a unified image generation model that can generate a wide range of images from multi-modal prompts. It is…
In the rapidly evolving landscape of Artificial General Intelligence (AGI), the emergence of Florence-2 signifies a monumental stride forward in the realm of computer vision. Developed by a team at Azure AI, Microsoft, this state-of-the-art vision foundation model aims to redefine the way machines comprehend and interpret visual data. Let's delve into this groundbreaking advancement and explore how Florence-2 is poised to revolutionize the field of AI. (you have nodes in comfyui to use florence)
https://www.labellerr.com/blog/florence-2-vision-model-by-microsoft/
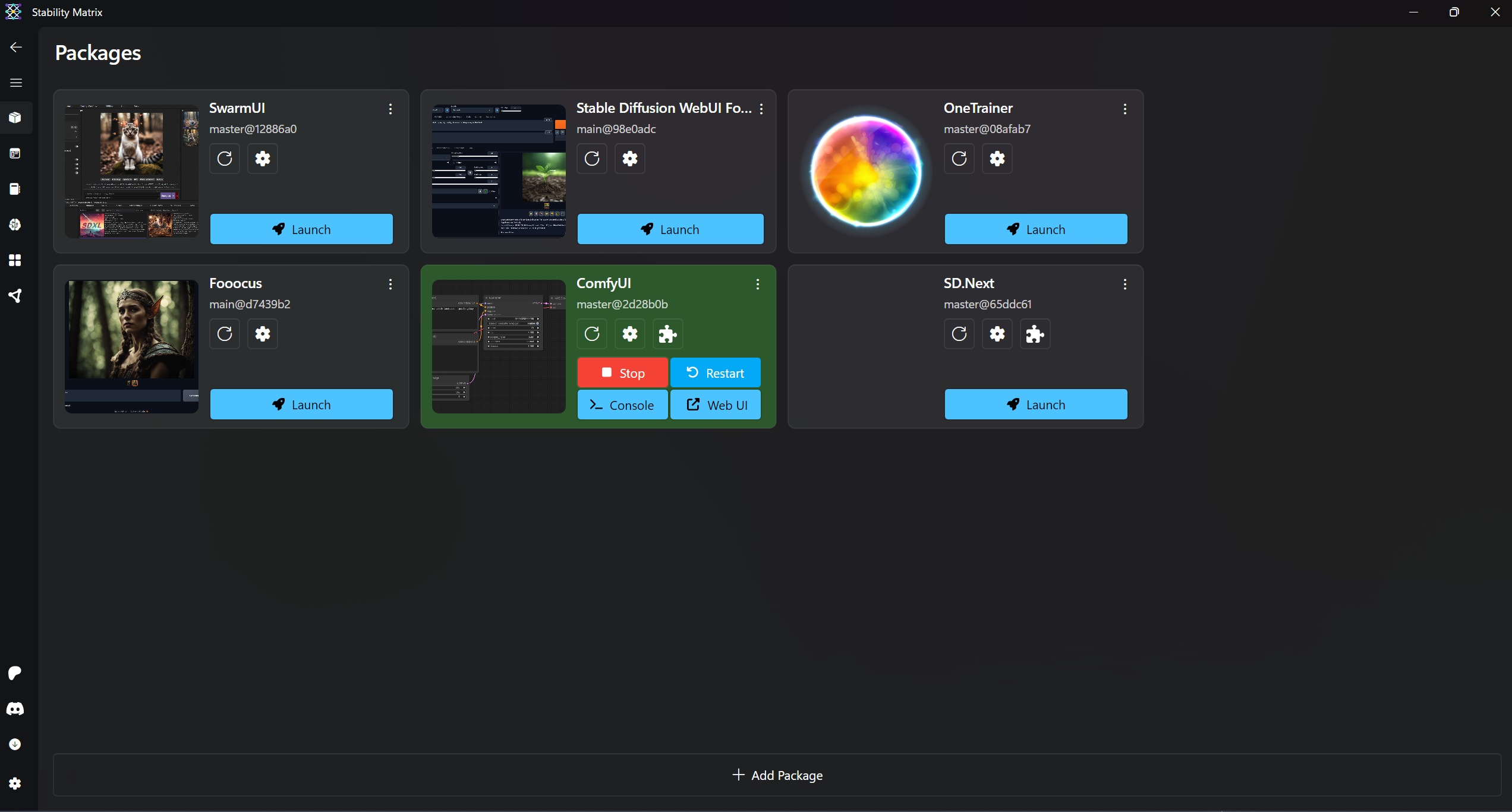
On a closing note, let me introduce again stability matrix, a one system to manage all your AI art needs (it can install various interfaces like sdwebui and its variants forge,SDnext, comfyui, invokeai, foocus, swarmui, onetrainer ), it works mostly great, Im only running invokeai separately as of now. Makes easy keeping track of things, hopefully it will integrate some llm solutions, NERF, TD UE plugins too in future as a full multimodal system though as of now these need to installed separately
LykosAI
/
StabilityMatrix
Multi-Platform Package Manager for Stable Diffusion
Stability Matrix
![]()


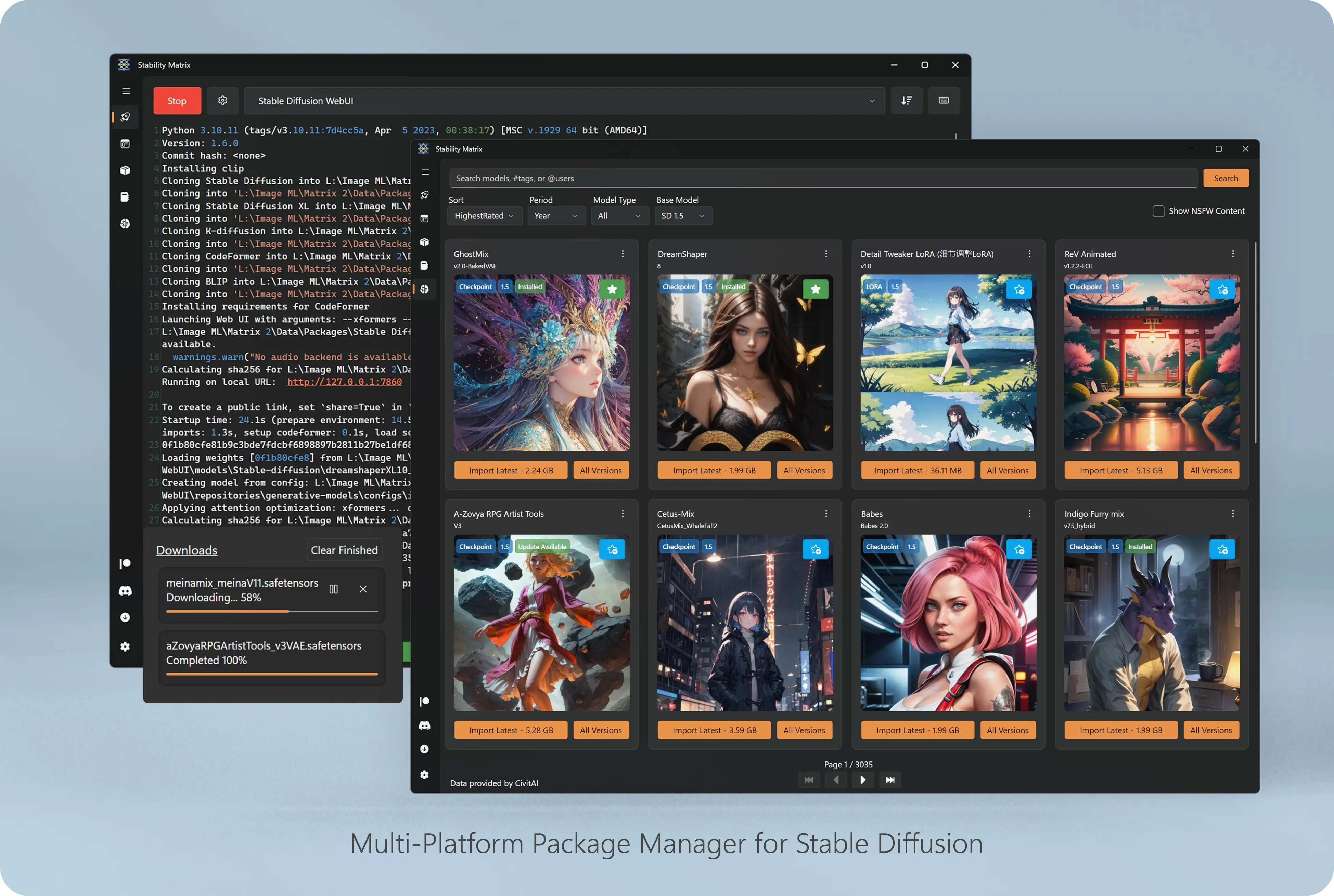
Multi-Platform Package Manager and Inference UI for Stable Diffusion
🖱️ One click install and update for Stable Diffusion Web UI Packages
- Supports
- Stable Diffusion WebUI reForge, Stable Diffusion WebUI Forge, Stable Diffusion WebUI AMDGPU Forge Automatic 1111, Automatic 1111 DirectML, SD Web UI-UX, SD.Next
- Fooocus, Fooocus MRE, Fooocus ControlNet SDXL, Ruined Fooocus, Fooocus - mashb1t's 1-Up Edition, SimpleSDXL
- ComfyUI
- StableSwarmUI
- VoltaML
- InvokeAI
- SDFX
- Kohya's GUI
- OneTrainer
- FluxGym
- CogVideo via CogStudio
- Manage plugins / extensions for supported packages (Automatic1111, Comfy UI, SD Web UI-UX, and SD.Next)
- Easily install or update Python dependencies for each package
- Embedded Git and Python dependencies, with no need for either to be globally installed
- Fully portable - move Stability Matrix's Data Directory to a new drive or computer at any time




Discussion (0)