AI generate video, image, and audio from text prompts or video, image, or text strips.
https://github.com/tin2tin/Generative_AI/assets/1322593/7cd69cd0-5842-40f0-b41f-455c77443535
Features
- Text to video
- Text to audio
- Text to speech
- Text to image
- Image to image (refinement+prompt)
- Image to video (refinement+prompt)
- Video to video (refinement+prompt)
- Style selector.
- Seed, quality steps, frames, word power, denoising, strip power.
- Batch conversion of text and media strips into videos, audio, music, speech, or images.
- Batch refinement of images.
- Batch upscale & refinement of movies.
- Model card selector.
- Render-to-path selector.
- Render finished notification.
- Model Cards: Stable Diffusion 1.5, 2, XL, Deep Floyd IF, Zeroscope, Animov, AudioLMD2 and Bark.
- One click install and uninstall dependencies.
- User-defined file path for generated files.
- Seed and prompt added to strip name.
Requirements
- Windows or Linux (Could maybe work on MacOS, but someone will have to contribute code to make it work).
- A CUDA-supported Nvidia card with at least 4 GB VRAM.
How to install
(As for Linux, if anything differs in installation, then please share instructions.)
First you must download and install git for your platform(must be on PATH(or Bark will fail)): https://git-scm.com/downloads
Download the add-on: https://github.com/tin2tin/text_to_video/archive/refs/heads/main.zip
On Windows, right-click on the Blender icon and "Run Blender as Administrator"(or you'll get write permission errors).
Install the add-on as usual: Preferences > Add-ons > Install > select file > enable the add-on.
In the Generative AI add-on preferences, hit the "Install all Dependencies" button.
Note that you can change what model cards are used in the various modes here(video, image, and audio).
Then it writes that it is finished(if any errors, let me know).
Restart Blender.
Open the add-on UI in the Sequencedr > Sidebar > Generative AI.
The first time any model is executed many GB will have to be downloaded, so go grab lots of coffee.
If it says: "ModuleNotFoundError: Refer to https://github.com/facebookresearch/xformers for more information on how to install xformers", then try to restart Blender.
| Tip |
|---|
| If any Python modules are missing, use this add-on to manually install them: |
| https://github.com/amb/blender_pip |
Location
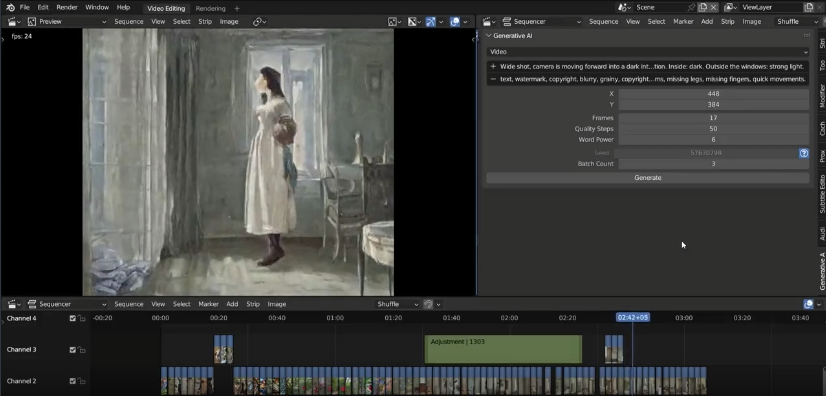
Install Dependencies, set Movie Model Card, and set Sound Notification in the add-on preferences:
Video Sequence Editor > Sidebar > Generative AI:
Styles:
Text to Video/Image
The Animov models have been trained on Anime material, so adding "anime" to the prompt is necessary, especially for the Animov-512x model.
The Stable Diffusion models for generating images have been used a lot, so there are plenty of prompt suggestions out there if you google for them.
The Modelscope model has a watermark, since it's been trained on Shutterstock material, and can't be used for commercial purposes.
| Tip |
|---|
| If the image of your renders breaks, then use the resolution from the Model Card in the Preferences. |
| Tip |
|---|
| If the image of your playback stutters, then select a strip > Menu > Strip > Movie Strip > Set Render Size. |
| Tip |
|---|
| If you get the message that CUDA is out of memory, then restart Blender to free up memory and make it stable again. |
Batch Processing
Select multiple strips and hit Generate. When doing this, the file name, and if found the seed value, is automatically inserted into the prompt and seed value.
Text to Audio
Bark
Find Bark documentation here: https://github.com/suno-ai/bark
- [laughter]
- [laughs]
- [sighs]
- [music]
- [gasps]
- [clears throat]
- — or ... for hesitations
- ♪ for song lyrics
- capitalization for emphasis on a word
- MAN/WOMAN: for bias towards the speaker
Speaker Library: https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683?v=bc67cff786b04b50b3ceb756fd05f68c
| Tip |
|---|
| If the audio breaks up, try processing longer sentences. |
AudioLDM2
Find AudioLDM documentation here: https://github.com/haoheliu/AudioLDM
Try prompts like: Bag pipes playing a funeral dirge, punk rock band playing hardcore song, techno dj playing deep bass house music, and acid house loop with jazz.
Or: Voice of God judging mankind, woman talking about celestial beings, hammer on wood.
AI Modules
Diffusers: https://github.com/huggingface/diffusers
ModelScope: https://modelscope.cn/models/damo/text-to-video-synthesis/summary
Animov: https://huggingface.co/vdo/animov-0.1.1
Potat1: https://huggingface.co/camenduru/potat1
Zeroscope Dark: https://huggingface.co/cerspense/zeroscope_v2_dark_30x448x256
Zeroscope XL: https://huggingface.co/cerspense/zeroscope_v2_XL
AudioLDM2 Music: https://huggingface.co/cvssp/audioldm-s-full-v2 https://github.com/haoheliu/AudioLDM
Bark: https://github.com/suno-ai/bark
Deep Floyd IF: https://github.com/deep-floyd/IF
Stable Diffusion XL: https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9
Uninstall
Hugging Face diffusers model is downloaded from the hub and saved to a local cache directory. By default, the cache directory is located at:
On Linux and macOS: ~/.cache/huggingface/transformers
On Windows: %userprofile%\.cache\huggingface\transformers
Here you can locate and delete the individual models.
Video Examples
Zeroscope & Bark:


Video to video:
https://github.com/tin2tin/Generative_AI/assets/1322593/c044a0b0-95c2-4b54-af0b-45bc0c670c89
https://github.com/tin2tin/Generative_AI/assets/1322593/0105cd35-b3b2-49cf-91c1-0633dd484177
Img2img:
https://github.com/tin2tin/Generative_AI/assets/1322593/2dd2d2f1-a1f6-4562-8116-ffce872b79c3
Restrictions for using the AI models:
- The models can only be used for non-commercial purposes. The models are meant for research purposes.
- The models was not trained to realistically represent people or events, so using it to generate such content is beyond the model's capabilities.
- It is prohibited to generate content that is demeaning or harmful to people or their environment, culture, religion, etc.
- Prohibited for pornographic, violent, and bloody content generation.
- Prohibited for error and false information generation.
 tin2tin
/
Pallaidium
tin2tin
/
Pallaidium
PALLAIDIUM - a generative AI movie studio integrated in the Blender video editor.
PALLAIDIUM
A generative AI movie studio integrated into the Blender Video Editor.
 AI-generate video, image, and audio from text prompts or video, image, or text strips.
AI-generate video, image, and audio from text prompts or video, image, or text strips.Features
Text to video
Text to image
Text to text
Text to speech
Text to audio
Text to music
Image to image
Image to video
Image to text
Video to video
Video to Image
Video to text
ControlNet
OpenPose
Canny
ADetailer
IP Adapter Face
IP Adapter Style
Multiple LoRAs
LoRA Weight
Style selector
Seed
Quality steps
Strip power
Frames (Duration)
Word power
Model card selector
Batch conversion
Batch refinement of images.
Prompt batching
Batch upscale & refinement of movies.
Render-to-path selector.
Render finished notification.
User-defined file path for generated files.
Seed and prompt added to strip name.
One-click install and uninstall dependencies.
Requirements
- Windows (Unsupported: Linux and MacOS).
- A CUDA-supported Nvidia card with at least 6 GB VRAM.
- CUDA: 12.4
- 20+ GB HDD. (Each…






Discussion (1)
Nice updates on blender and gimp. There is also alpaca for photoshop. And Visions of chaos often doesnt get mentioned but helps you install different things related to AI and fractals. The post actually spoke about audio AI, which got me interested and helped me discover this new DAW tuneflow.com