New update
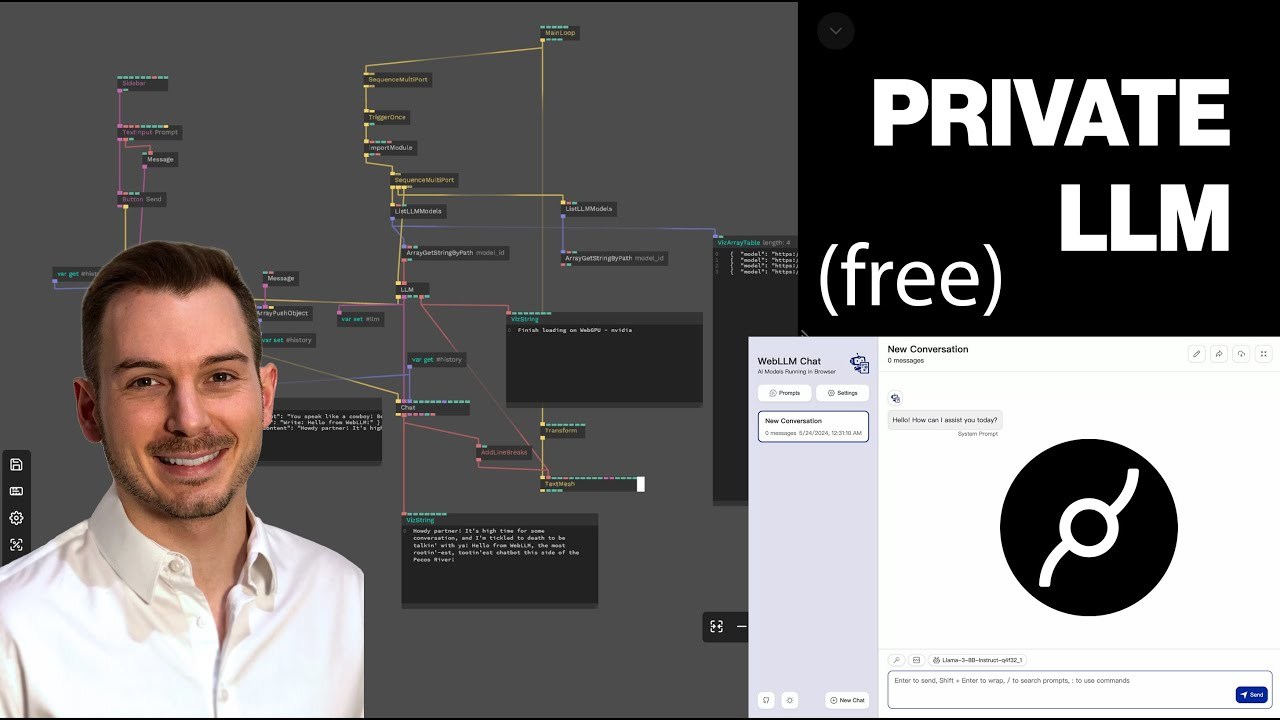
Get ready to see the future of web development in action! In this video, we’re diving into how Large Language Models (LLMs) are now running directly in your browser thanks to WebLLM and Cables.gl. No API calls — just instant power using WebAssembly and WebGPU. We’ll walk you through setting up models, building interactive chat features, and exploring powerful new tools that bring a whole new level of intelligence to your web experiences. Let’s push the limits of what’s possible on the web!
WebLLM: https://webllm.mlc.ai/
Link to patch: https://cables.gl/edit/XsRWUl
🚀 Introduction to Web LLMs: 00:00
- Introduced Web LLMs as a way to run language models in the browser
- Highlighted the ability to run models without API calls or sending data to third parties
- Mentioned the use of WebAssembly and WebGPU for running models
- Introduced the integration of Web LLM framework into Cables
💻 Setting up Web LLM in Cables: 05:00
- Demonstrated how to import the Web LLM module into Cables
- Explained the process of listing available LLM models
- Showed how to filter models based on name and VRAM requirements
- Demonstrated loading a selected model (Gemma 2B) into Cables
🗨️ Creating a Simple Chat Interface: 15:00
- Created a basic chat interface using Cables ops
- Explained the process of converting user input into messages for the LLM
- Demonstrated how to add system prompts to guide the model's responses
- Showed how to maintain conversation history for context
🔍 Advanced Features and Analysis: 25:00
- Demonstrated how to analyze the conversation history using the LLM
- Explained the process of creating meta-prompts for analysis
- Showed how to format prompts to get structured JSON responses from the model
- Discussed the limitations of smaller models and the need for stronger ones
🚀 Exploring Larger Models: 35:00
- Switched to a larger Llama 3 model to demonstrate increased capabilities
- Discussed the trade-offs between model size, performance, and resource requirements
- Highlighted the challenges of using large models in web applications
🚀 Ready to join a community where creativity meets data? Connect with us on Discord! Click here: / discord and become a part of the vibrant decode.gl family. Whether you're looking to share your latest project, get feedback, or find someone to collaborate with, our Discord channel is the perfect place to start.
Don't forget to explore more about what we do and dive deeper into the world of interactive experiences and digital art by visiting our website: https://decode.gl. This is where your creative journey takes flight, surrounded by a community of innovators and enthusiasts just like you. We're excited to see what you'll create and contribute to our collective exploration of data and art. Join us now and let's make something amazing together! 🌐🎨🤝





Discussion (2)
amazing :)
Cool